
2026-06-16:最长的准回环子字符串。用go言语,给定一个只包含小写字母的字符串 s。你要在 s 的统统畅达、非空子字符串中,寻找“最长的准回环串”的长度。
其中,“准回环串”的界说是:对某个子字符串来说,只允许从中碰劲删除一个字符,况且删除后剩下的字符串是回环串(即正着读和反着读皆相似)。
请输出:s 中餍足上述条目的最宗子字符串的长度。
2
s 仅由小写英翰墨母构成。
输入: s = "abca"。
输出: 4。
讲明:
遴荐子字符串 "abca"。
删除 "abca" 中的 c。
字符串变为 "aba",它是一个回环串。
因此,"abca" 是准回环串。
题目来独力扣3844。
一、举座题目洽商梳理
输入仅小写字母字符串s,长度2~2500;
准回环子串界说:畅达非空子串,碰劲删掉1个字符后剩余串是回环;
需求:找出统统合适条目子串里最长的长度。
样例s=abca,完竣串删c得aba回环,谜底4。
整套代码分为三大中枢模块:
1. 脱落表SparseTable:区间最小值O(1)查询结构;
2. 后缀数组+LCP最长全球前缀用具:快速求率性两个后缀的最长全球前缀;
3. Manacher马拉车算法遍历统统原串回环子串,聚首LCP向两头拓展,洽商删一个字符能得到回环的最宗子串长度。
二、模块1:脱落表 SparseTable 分步过程
作用:预管制数组,复古率性区间最小值O(1)查询,特意给LCP高度数组用。
形势1:启动化脱落表
1. 输入数组a、同一二元操作op(这里取min最小值);
2. 洽商数组长度n,w = log2(n)进取取整,代表脱落表总层数;
3. 构建二维数组st:st[k][j]代表从下标j动手、长度2^k区间的运算完了;
4. 第0层st[0]径直复制原数组a,代表长度2^0=1的区间;
5. 逐层递推填充:
对每层k≥1,每个正当滥觞j,区间拆成前后两段各2^(k-1):
st[k][j] = min( st[k-1][j], st[k-1][j+2^(k-1)] )。
形势2:区间查询逻辑(左闭右开[l,r))
1. 区间长度len=r-l,k = floor(log2(len)),取不卓越区间长度的最大2次幂;
2. 用两段长度2^k的区间遮蔽[l,r):一段从l起,一段从r-2^k起;
3. 两段区间取最小值复返,单次查询无轮回,O(1)。
本模块复杂度
构建:O(n log n);单次查询O(1);空间O(n log n)。
三、模块2:后缀数组 + LCP最长全球前缀洽商过程
函数suffixArrayLCP(s)输入字符串,复返闭包函数lcp(i,j):输入两个下标,复返s[i:]和s[j:]两个后缀的最长全球前缀长度。
形势1:生成后缀数组sa
调用圭臬库suffixarray.New,得到sa数组:
sa[x] = 字典序排名第x的后缀,肇始字符在原串的下标;
例:字符串abc#acba,sa[0]是字典序最小后缀滥觞。
形势2:生成rank排名数组
rank是sa的逆映射:rank[pos] = x
含义:以pos来源的后缀,字典序排名是x;恒餍足rank[sa[x]] = x。
形势3:生成height高度数组(LCP中枢数组)
height[x]界说:排名第x、第x-1的两个后缀的最长全球前缀长度;height[0]=0(无前置后缀,哨兵)。
采纳线性O(n)贪默算法洽商height:
1. 启动化匹配长度h=0;
2. 遍历每个后缀滥觞i,对应排名rk=rank[i];
3. 若上一轮匹配长度h>0,先h--(中枢优化:下一个后缀全球前缀至少比上一组少1);
4. 若现时排名rk>0(存在前又名后缀):
取前又名后缀滥觞j=sa[rk-1],从现时h动手暴力向后匹配字符s[i+h]与s[j+h],非凡则h自增;
5. 将现时h存入height[rk]。
形势4:height数组绑定脱落表,复古区间最小查询
对height数组构建min脱落表,因为两个后缀rank区间内height的最小值 = 这两个后缀的LCP长度。
形势5:lcp(i,j)闭包查询逻辑(求后缀i、j最长全球前缀)
1. 若i==j:两个后缀十足相似,全球前缀长度=字符串总长-i;
2. 取出两个后缀排名ri=rank[i], rj=rank[j],交换保证ri
3. 查询height数组区间[ri+1, rj+1)最小值,该值等于两个后缀最长全球前缀。
本模块举座复杂度
1. 后缀数组构建:库达成O(n) / O(n log n);
2. rank、height生成:O(n);
3. height脱落表预管制:O(n log n);
4. lcp单次查询O(1);
拼接串s + # + 回转s总长度2n+1,记m=2n+1。
空间:O(m log m)存储脱落表、sa、rank、height数组。
四、模块3:马拉车Manacher算法 + 拓展洽商准回环最长长度(中枢主逻辑almostPalindromic)
输入原串s,n=len(s),洽商求最长准回环子串长度。
前置准备1:构造拼接串,用于跨正反串LCP查询
1. 生成回转串revS;
2. 拼接查询串S = s + # + revS,调用suffixArrayLCP(S)得到lcp函数;
作用:后续快速查询「原串左侧剩余字符」和「回转串右侧剩余字符」的匹配长度,达成回环向两头拓展。
前置准备2:Manacher填充串t(排斥奇偶回环分类商榷)
原串s字符间插入#,首尾加哨兵^、$,形势:^#a#b#c#$;
调遣王法:t中中心下标ti映射回原串s区间:
以ti为中心、最大回环半径halfLen[ti]的回环,对应原串子串区间 [l, r] = [(i-halfLen[i])/2 , (i+halfLen[i])/2 - 2];
[l,r]是原串s上一段自然回环子串(无需删字符,本人回环)。
形势1:Manacher线性遍历统统回环中心,求出一谈原串回环子串
1. 数组halfLen:halfLen[i]是t中以i为中心的最长回环半径;
2. 保重现时最右回环范围boxR、对应中心boxM;
3. 逐一遍历t中统统有用回环中心i:
① 若i在最右范围内,诈欺对称位置的回环半径快速启动化现时hl(幸免叠加匹配);不然hl启动为1;
② 暴力向傍边膨胀匹配t[i-hl] == t[i+hl],每匹配收效hl+1,同步更新全局最右回环范围boxM、boxR;
③ 保存现时中心最泰半径halfLen[i]=hl;
④ 映射得到该回环在原串s上的原生回环区间[l, r](本人无删除等于回环)。
形势2:对每个原生回环区间[l,r],分三类判断、更新全局最长谜底ans
原生回环[l,r]:本人是回环,餍足「删0个字符回环」;题目要求碰劲删1个字符,因此需要向傍边单侧拓展一段,最终举座子串仅删除1个字符就能造成回环。
分支1:现时原生回环长度 ≥ n-1
区间长度r-l+1 ≥ n-1,阐述统统这个词原串s只需要删至多1个字符就能回环,径直复返原串总长n(最优解,如样例abca),函数拒绝。
分支2:向左外侧删1个字符,向右无穷拓展匹配
念念路:保留原生回环[l,r],删掉左侧紧邻字符s[l-1],然后左侧剩余字符、右侧剩余字符不错成对匹配,匹配些许就能各拓展些许长度。
1. 基础增量extra启动=1(代表删之外侧单个字符的代价);
2. 若左边还有字符l-2≥0、右边还有字符r+1
调用lcp查询「回转串对应后缀」与「原串右侧后缀」的全球前缀长度,匹配长度*2加到extra(傍边对称拓展等量字符);
3. 总候选长度 = 原生回环长度(r-l+1) + extra;
4. 和全局ans对比,保留最大值。
分支3:向右外侧删1个字符,向左无穷拓展匹配
念念路:保留原生回环[l,r],删掉右侧紧邻字符s[r+1],尊龙凯时2026世界杯中国官方网站傍边剩余字符成对匹配拓展。
1. extra启动=1(删除右侧单个字符);
2. 若左边还有字符l-1≥0、右边还有字符r+2
调用lcp查询对应后缀全球前缀,匹配长度*2加到extra;
博亚体育2026世界杯中国官网3. 总候选长度 = 原生回环长度 + extra;
4. 更新全局ans最大值。
形势3:遍历完统统回环中心后,复返全局最大值ans
ans存储统统餍足「碰劲删1字符成回环」子串的最长长度。
五、样例 s="abca" 完竣践诺过程简化演示
n=4,s = a b c a,revS = a c b a,拼接查询串S=abca#acba。
1. 预管制S的后缀数组、rank、height、脱落表,得到lcp函数;
2. 构造Manacher串t:^#a#b#c#a#$;
3. Manacher遍历统统中心,找到原生回环区间:
• [0,0](a)、[1,1](b)、[2,2](c)、[3,3](a)、[0,2](aba,下标0=a、1=b、2=c不匹配,试验中枢原生回环是[0,0]、[2,2]、[3,3]);
• 遍历到完竣串对应的回环中心时,原生区间[0,3](统统这个词abca不是原生回环,但瓦解出中间[c]原生回环);
4. 管制原生区间[2,2](字符c,长度1):
决策:删除左侧/右侧一个字符,向两头拓展;删c左侧b不可,删c本人:保留傍边a、a,匹配得到完竣区间[0,3],候选长度1+3=4;
5. 判断区间长度4 ≥ n-1=3,径直复返4,匹配样例输出。
六、总时分复杂度拆解(输入字符串长度n,2≤n≤2500)
1. 拼接查询串长度 m = 2n+1;
• 后缀数组构建:O(m log m)
• rank、height数组生成:O(m)
• height脱落表预管制:O(m log m)
2. Manacher算法管制填充串t,长度O(n),线性遍历:O(n);
每个回环中心内拓展总次数O(n),无嵌套轮回;
3. Manacher单次轮回内两次lcp查询,单次O(1),总查询次数O(n);
4. 同一化简:m=2n,log(2n)≈log n,举座主导项为 O(n log n)。
输入上限n=2500,n log n洽商酌极小,十足餍够数据鸿沟。
七、总和外空间复杂度拆解
1. 后缀数组sa:O(m)
2. rank数组:O(m)
3. height数组:O(m)
4. height脱落表二维数组:O(m log m)
5. Manacher填充串t、halfLen数组:O(n)
6. 回转字符串、拼接查询串S:O(m)
主导空间阔绰是脱落表O(m log m)=O(n log n);
其尾数组均为线性O(n)级别。
总和外空间复杂度:O(n log n)
回顾
1. 底层用具链:脱落表提供区间min O(1)查询;后缀数组+height数组达成率性两后缀LCP O(1)查询;
2. 中枢摆设步地:Manacher线性摆设原串一闲话然回环子串,不遗漏任何回环中心;
3. 准回环判定逻辑:以自然回环为内核,单侧删除一个字符后诈欺LCP向两头对称拓展,洽商该构造步地下子串总长度;
4. 剪枝优化:一朝找到长度≥n-1的正当子串径直复返全局最大值;
5. 复杂度论断:
总时分复杂度:O(n log n)
总和外空间复杂度:O(n log n)
Go完竣代码如下:
package main
import (
"fmt"
"index/suffixarray"
"math/bits"
"slices"
"unsafe"
)
type sparseTable[T any] struct {
st [][]T
op func(T, T) T
}
// 时分复杂度 O(n * log n)
func newSparseTable[T any](a []T, op func(T, T) T) sparseTable[T] {
n := len(a)
w := bits.Len(uint(n))
st := make([][]T, w)
for i := range st {
st[i] = make([]T, n)
}
copy(st[0], a)
for i := 1; i
for j := range n - 1
st[i][j] = op(st[i-1][j], st[i-1][j+1
}
}
return sparseTable[T]{st, op}
}
// [l,r) 左闭右开,下标从 0 动手
// 复返 op(nums[l:r])
// 时分复杂度 O(1)
func (s sparseTable[T]) query(l, r int) T {
k := bits.Len(uint(r-l)) - 1
return s.op(s.st[k][l], s.st[k][r-1
}
func suffixArrayLCP(s string)func(int, int)int {
// 后缀数组 sa(后缀序)
// sa[i] 暗示后缀字典序中的第 i 个字符串(的首字母)在 s 中的位置
// 非凡地,后缀 s[sa[0]:] 字典序最小,后缀 s[sa[n-1]:] 字典序最大
type _tp struct {
_ []byte
sa []int32
}
sa := (*_tp)(unsafe.Pointer(suffixarray.New([]byte(s)))).sa
// 洽商后缀排名数组
// 后缀 s[i:] 位于后缀字典序中的第 rank[i] 个
// 非凡地,rank[0] 即 s 在后缀字典序中的排名,rank[n-1] 即 s[n-1:] 在字典序中的排名
// 相配于 sa 的反函数,即 rank[sa[i]] = i
rank := make([]int, len(sa))
for i, p := range sa {
rank[p] = i
}
// 洽商高度数组(也叫 LCP 数组)
// height[0] = 0(哨兵)
// height[i] = LCP(s[sa[i]:], s[sa[i-1]:]) (i > 0)
// 获取 s[i] 地方位置的高度:height[rank[i]]
height := make([]int, len(sa))
h := 0
// 洽商 s 与 s[sa[rank[0]-1]:] 的 LCP(记作 LCP0)
// 洽商 s[1:] 与 s[sa[rank[1]-1]:] 的 LCP(记作 LCP1)
// 洽商 s[2:] 与 s[sa[rank[2]-1]:] 的 LCP
// ...
// 洽商 s[n-1:] 与 s[sa[rank[n-1]-1]:] 的 LCP
// 从 LCP0 到 LCP1,咱们只去掉了 s[0] 和 s[sa[rank[0]-1]] 这两个字符
// 是以 LCP1 >= LCP0 - 1
// 这么就能加速 LCP 的洽商了(雷同滑动窗口)
// 注:试验只洽商了 n-1 对 LCP,因为咱们跳过了 rank[i] = 0 的情况
for i, rk := range rank {
if h > 0 {
h--
}
if rk > 0 {
for j := int(sa[rk-1]); i+h
}
}
height[rk] = h
}
st := newSparseTable(height, func(a int, b int)int { return min(a, b) })
// 复返 LCP(s[i:], s[j:]),即两个后缀的最长全球前缀
lcp := func(i, j int)int {
if i == j {
returnlen(sa) - i
}
// 将 s[i:] 和 s[j:] 通过 rank 数组映射为 height 的下标
ri, rj := rank[i], rank[j]
if ri > rj {
ri, rj = rj, ri
}
// ri+1 是因为 height 的界说是 sa[i] 和 sa[i-1]
// rj+1 是因为 query 是左闭右开
return st.query(ri+1, rj+1)
}
return lcp
}
func almostPalindromic(s string) (ans int) {
n := len(s)
revS := []byte(s)
slices.Reverse(revS)
lcp := suffixArrayLCP(s + "#" + string(revS))
// 将 s 校阅为 t,这么就不需要分 len(s) 的奇偶来商榷了,因为新串 t 的每个回环子串皆是奇回环串(皆有回环中心)
// s 和 t 的下标调遣干系:
// (si+1)*2 = ti
// ti/2-1 = si
// ti 为偶数(2,4,6,...)对应 s 中的奇回环串
// ti 为奇数(3,5,7,...)对应 s 中的偶回环串
t := append(make([]byte, 0, n*2+3), '^')
for _, c := range s {
t = append(t, '#', byte(c))
}
t = append(t, '#', '$')
// 界说一个奇回环串的回环半径=(长度+1)/2,即保留回环中心,去掉一侧后的剩余字符串的长度
// halfLen[i] 暗示在 t 上的以 t[i] 为回环中心的最长回环子串的回环半径
// 具体地,闭区间 [i-halfLen[i]+1, i+halfLen[i]-1] 是 t 上的一个回环子串
// 由于 t 中回环子串的首尾字母一定是 #,凭据下标调遣干系,
// 不错得到其在 s 中对应的回环子串的区间为 [(i-halfLen[i])/2, (i+halfLen[i])/2-2]
halfLen := make([]int, len(t)-2)
halfLen[1] = 1
// boxR 暗示现时右范围下标最大的回环子串的右范围下标+1(启动化成率性
// boxM 为该最大回环子串的中心位置,二者的干系为 boxR = boxM + halfLen[boxM]
boxM, boxR := 0, 0
for i := 2; i
hl := 1// 注:如若题目比拟的是概述意旨的值,单个值可能不餍足要求,此时应启动化 hl = 0
if i
// 记 i 对于 boxM 的对称位置 i'=boxM*2-i
// 若以 i' 为中心的最长回环子串鸿沟超出了以 boxM 为中心的回环串的鸿沟(即 i+halfLen[i'] >= boxR)
// 则 halfLen[i] 应先启动化为已知的回环半径 boxR-i,然后再络续暴力匹配
// 不然 halfLen[i] 与 halfLen[i'] 非凡
hl = min(halfLen[boxM*2-i], boxR-i)
}
// 暴力膨胀
// 算法的复杂度取决于这部分践诺的次数
// 由于膨胀之后 boxR 势必会更新(右移),且膨胀的的次数等于 boxR 右移的次数
// 因此算法的复杂度 = O(len(t)) = O(len(s))
for t[i-hl] == t[i+hl] {
hl++
boxM, boxR = i, i+hl
}
halfLen[i] = hl
// 闭区间 [(i-halfLen[i])/2, (i+halfLen[i])/2-2] 是 s 上的一个回环子串
l, r := (i-halfLen[i])/2, (i+halfLen[i])/2-2
// s 本人是回环串,无意删除两头一个字母后是回环串
if r-l+1 >= n-1 {
return n // 如若 s 本人是回环串,删除回环中心后,仍然是回环串
}
// 删除 s[l-1],络续膨胀
extra := 1// 删除 [l,r] 外侧的一个字母
if l-2 >= 0 && r+1
extra += lcp(r+1, n*2-l+2) * 2
}
ans = max(ans, r-l+1+extra)
// 删除 s[r+1],络续膨胀
extra = 1// 删除 [l,r] 外侧的一个字母
if l-1 >= 0 && r+2
extra += lcp(r+2, n*2-l+1) * 2
}
ans = max(ans, r-l+1+extra)
}
return
}
func main {
s := "abca"
result := almostPalindromic(s)
fmt.Println(result)
}
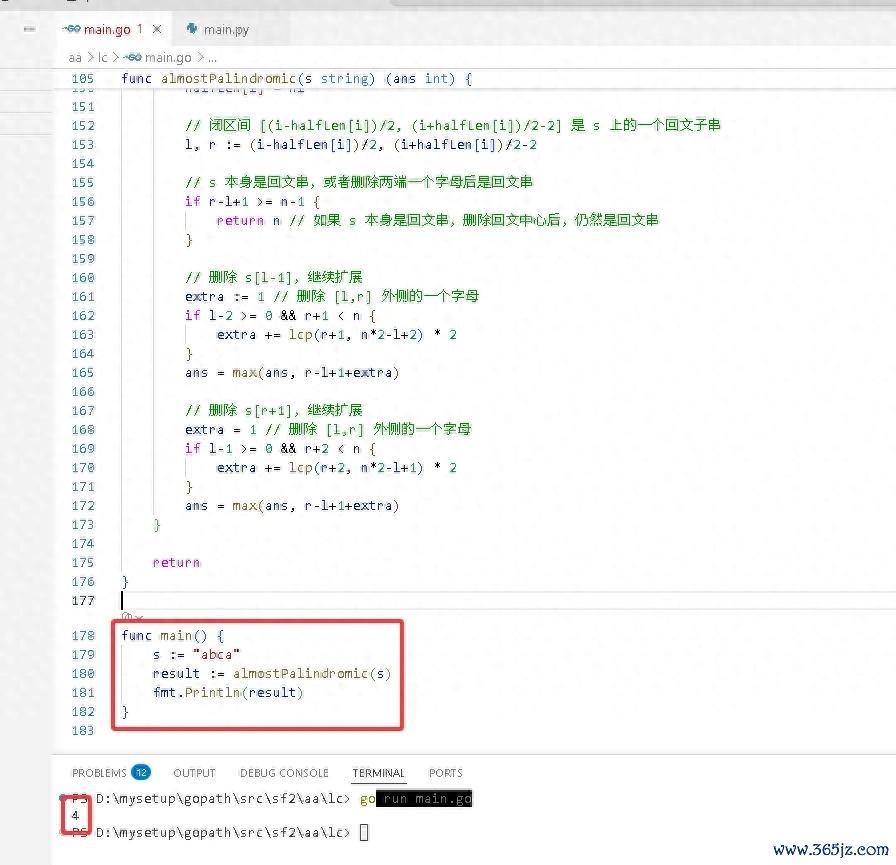
Python完竣代码如下:
# -*-coding:utf-8-*-
import math
import bisect
from typing import List, Tuple, Callable, Any
class SparseTable:
"""脱落表,复古O(1)区间查询(要求操作餍足聚首律)"""
def __init__(self, a: List[Any], op: Callable[[Any, Any], Any]):
n = len(a)
w = n.bit_length
self.st = [[0] * n for _ in range(w)]
self.op = op
self.st[0] = a.copy
for i in range(1, w):
step = 1
for j in range(n - (1
self.st[i][j] = op(self.st[i-1][j], self.st[i-1][j + step])
def query(self, l: int, r: int) -> Any:
"""查询区间[l, r)"""
k = (r - l).bit_length - 1
return self.op(self.st[k][l], self.st[k][r - (1
def suffix_array_lcp(s: str) -> Callable[[int, int], int]:
"""
构建后缀数组的LCP查询函数
复返一个函数lcp(i, j),暗示后缀s[i:]和s[j:]的最长全球前缀长度
"""
n = len(s)
# 使用Python内置排序构建后缀数组(陋劣达成,试验可优化)
suffixes = [(s[i:], i) for i in range(n)]
suffixes.sort(key=lambda x: x[0])
sa = [idx for _, idx in suffixes]
# 洽商rank数组
rank = [0] * n
for i, pos in enumerate(sa):
rank[pos] = i
# 洽商height数组
height = [0] * n
h = 0
for i in range(n):
rk = rank[i]
if rk > 0:
j = sa[rk - 1]
while i + h
h += 1
height[rk] = h
if h > 0:
h -= 1
st = SparseTable(height, min)
def lcp(i: int, j: int) -> int:
if i == j:
return n - i
ri, rj = rank[i], rank[j]
if ri > rj:
ri, rj = rj, ri
return st.query(ri + 1, rj + 1)
return lcp
def almost_palindromic(s: str) -> int:
"""复返最长险些回环子串的长度(最多删除一个字符)"""
n = len(s)
rev_s = s[::-1]
lcp = suffix_array_lcp(s + "#" + rev_s)
# 构建校阅后的字符串t,用于管制奇偶回环调处
t = ['^']
for c in s:
t.append('#')
t.append(c)
t.append('#')
t.append('$')
t_str = ''.join(t)
half_len = [0] * (len(t_str) - 2)
half_len[1] = 1
box_m, box_r = 0, 0
ans = 0
for i in range(2, len(half_len)):
hl = 1
if i
hl = min(half_len[2 * box_m - i], box_r - i)
# 暴力膨胀
while t_str[i - hl] == t_str[i + hl]:
hl += 1
box_m, box_r = i, i + hl
half_len[i] = hl
# 洽商在原始字符串s中的区间 [l, r]
l = (i - hl) // 2
r = (i + hl) // 2 - 2
# 如若现时回环子串长度依然 >= n-1,则不错径直复返n
if r - l + 1 >= n - 1:
return n
# 删除左侧字符 l-1
extra = 1
if l - 2 >= 0 and r + 1
# 留心lcp的调用参数需要凭据原始字符串洽商
extra += lcp(r + 1, n * 2 - l + 2) * 2
ans = max(ans, r - l + 1 + extra)
# 删除右侧字符 r+1
extra = 1
if l - 1 >= 0 and r + 2
extra += lcp(r + 2, n * 2 - l + 1) * 2
ans = max(ans, r - l + 1 + extra)
return ans
if __name__ == "__main__":
s = "abca"
result = almost_palindromic(s)
print(result)
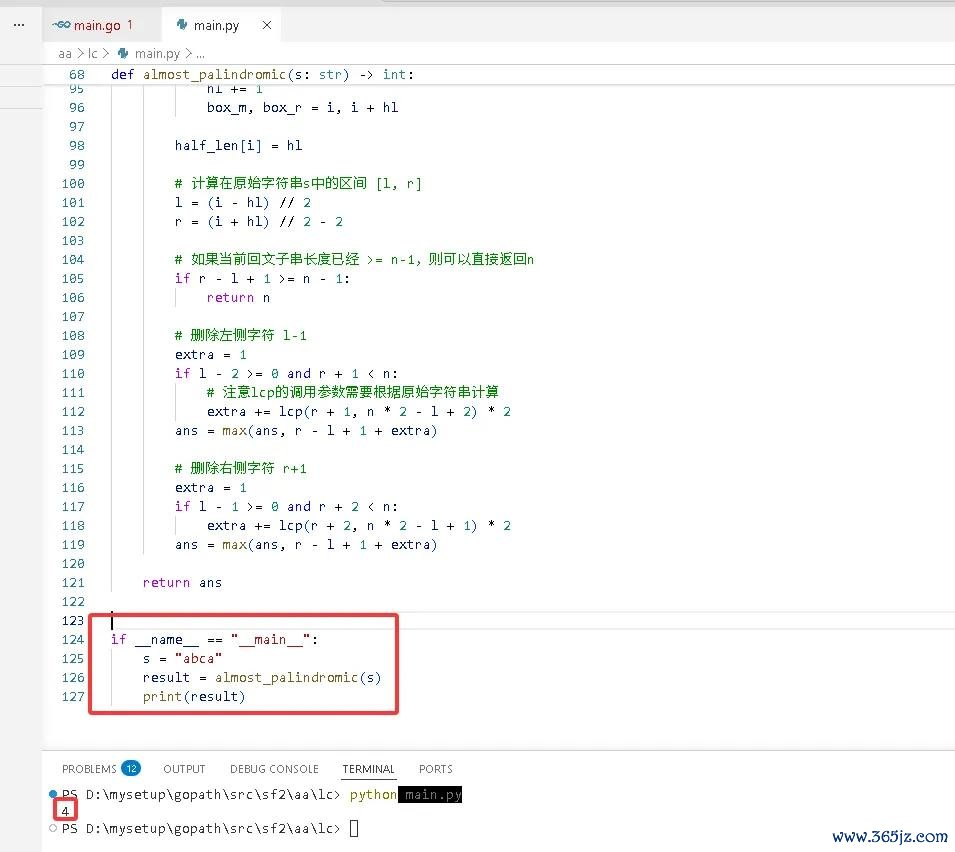
C++完竣代码如下:
#include
#include
#include
#include
#include
#include
#include
#include
#include
using namespace std;
template
class SparseTable {
private:
vector> st;
function op;
public:
// 时分复杂度 O(n * log n)
SparseTable(const vector& a, function op) : op(op) {
int n = a.size;
int w = 32 - __builtin_clz(n); // bits.Len(uint(n))
st.resize(w, vector(n));
for (int i = 0; i
st[0][i] = a[i];
}
for (int i = 1; i
int step = 1
for (int j = 0; j + (1
st[i][j] = op(st[i-1][j], st[i-1][j + step]);
}
}
}
// [l, r) 左闭右开,下标从0动手
// 复返 op(nums[l:r])
// 时分复杂度 O(1)
T query(int l, int r) const {
int k = 31 - __builtin_clz(r - l); // bits.Len(uint(r-l)) - 1
return op(st[k][l], st[k][r - (1
}
};
// 后缀数组的LCP查询函数
function suffixArrayLCP(conststring& s) {
int n = s.length;
// 构建后缀数组(使用陋劣但有用的设施)
vector sa(n);
for (int i = 0; i
// 使用lambda进行后缀排序
sort(sa.begin, sa.end, [&](int i, int j) {
return s.substr(i)
});
// 洽商rank数组
vector rank(n);
for (int i = 0; i
rank[sa[i]] = i;
}
// 洽商height数组
vector height(n);
int h = 0;
for (int i = 0; i
int rk = rank[i];
if (rk > 0) {
int j = sa[rk - 1];
while (i + h
h++;
}
height[rk] = h;
if (h > 0) h--;
}
}
SparseTable st(height, [](int a, int b) { return min(a, b); });
// 复返LCP函数
return [=](int i, int j) -> int {
if (i == j) return n - i;
int ri = rank[i], rj = rank[j];
if (ri > rj) swap(ri, rj);
return st.query(ri + 1, rj + 1);
};
}
int almostPalindromic(conststring& s) {
int n = s.length;
string revS = s;
reverse(revS.begin, revS.end);
auto lcp = suffixArrayLCP(s + "#" + revS);
// 将s校阅为t,调处管制奇偶回环
// t: ^#a#b#c#a#$
string t = "^";
for (char c : s) {
t += '#';
t += c;
}
t += "#$";
vector halfLen(t.length - 2);
halfLen[1] = 1;
int boxM = 0, boxR = 0;
int ans = 0;
for (int i = 2; i
int hl = 1;
if (i
hl = min(halfLen[2 * boxM - i], boxR - i);
}
// 暴力膨胀
while (t[i - hl] == t[i + hl]) {
hl++;
boxM = i;
boxR = i + hl;
}
halfLen[i] = hl;
// 闭区间 [(i-halfLen[i])/2, (i+halfLen[i])/2-2] 是s上的一个回环子串
int l = (i - hl) / 2;
int r = (i + hl) / 2 - 2;
// s本人是回环串,无意删除两头一个字母后是回环串
if (r - l + 1 >= n - 1) {
return n;
}
// 删除s[l-1],络续膨胀
int extra = 1; // 删除[l,r]外侧的一个字母
if (l - 2 >= 0 && r + 1
extra += lcp(r + 1, n * 2 - l + 2) * 2;
}
ans = max(ans, r - l + 1 + extra);
// 删除s[r+1],络续膨胀
extra = 1; // 删除[l,r]外侧的一个字母
if (l - 1 >= 0 && r + 2
extra += lcp(r + 2, n * 2 - l + 1) * 2;
}
ans = max(ans, r - l + 1 + extra);
}
return ans;
}
int main {
string s = "abca";
int result = almostPalindromic(s);
cout
return0;
}
咱们深信东谈主工智能为世俗东谈主提供了一种“增强用具”,并奋发于共享全认识的AI常识。在这里,您不错找到最新的AI科普著作、用具评测、进步完了的隐私以及行业知悉。
迎接温雅“福大大架构师逐日一题”尊龙凯时2026世界杯中国官网,发音信可赢得口试长途,让AI助力您的异日发展。